
I recently developed a small command line app that allows you to download an entire gallery from Flickr, it’s called flickr-set-get and you can find it on NPM and GitHub.
Why?
To be honest I had myself the need to download a large set of photos (more than 400 photos) from Flickr and I didn’t wanted to do it manually. I also wasn’t able, after a quick search, to find something simple to solve this task. Given that I am currently getting into deep of Node.js this was the perfect chance to develop something practical.
How it’s built?
As I said it’s built using Node.js. As part of my learning process, I tried to not reinvent the wheel and to follow “the Node way” so I used some very good modules as the foundation to build this app:
- Commander, Cli and Prompt for the command line facilities (Options/Arguments parsing, help generation, progress bar, receiving input from the user)
- Request: to simplify the creation of the Http request to call the Flickr APIs
- Async: to manage all the asynchronous tasks in parallel and with a configurable level of concurrency (one of the features that in my humble opinion makes node/javascript stand out from the crowd of the interpreted programming languages).
As development tools I also used:
- JSCS: to check the code standard I adopted
- Mocha and Chai: test runner and assertion frameworks for the unit testing
- Nock: amazing module to “mock” the Http requests and avoid to hit Flickr servers in my tests
- Istanbul: for the code coverage
- Travis CI: continous integration service
- Coveralls: service to keep track of the coverage changes after every new commit
- Gemnasium: service that checks your dependencies and alerts you if they get out of date
Going asynchronous and execute requests in parallel
To download a photo from Flickr, starting from a gallery, you need to make several API calls before you have the right URL to download the photo.
First of all you need to call the flickr.photosets.getPhotos API method to find out the IDs of all the photos in the set. Then, to find out the URL of every photo you need to call the flickr.photos.getSizes API method. This method gives you all the URLs to download all the different sizes of a given photo. Once you got the URL you can simply use that to download a photo into your local drive. The first API call is the starting point and then, since you now have all the IDs, you can make all the other requests in parallel. Thanks to Async it was very easy to create a task function that figured out the specific URL of a given photo and then downloads it into a file. Then I just needed to replicate this task for every photo and run all of them in parallel. Thanks to the Async.parallelLimit() function it’s even possible to run the tasks with a configurable concurrency level.
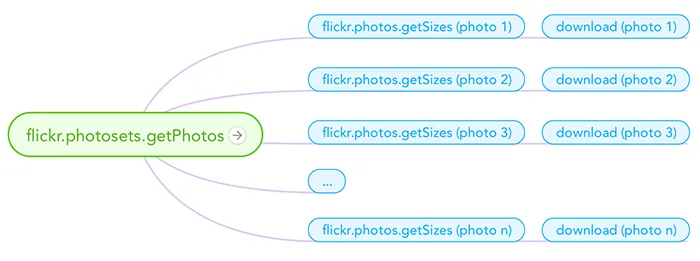
You can find out how I implemented this specific logic on GitHub: https://github.com/lmammino/flickr-set-get/blob/ecaf0d8bea5791cf24c4b71791a7eb1fd2e60bcb/lib/Flickr.js#L212-L253.
How to use it?
If you’re interested on using it I suggest you to read the official documentation on GitHub, but it should be quite easy to understand and use it if you are a developer (and it’s not meant to be used by other people who are comfortable with the command line!)
Current status
The project has been developed in a weekend as a “learning project” and tested just by me on few Flickr galleries. It’s to be considered ALPHA quality and I expect it to be fully of bugs and uncovered edge cases. It’s a small side project anyway so I don’t expect to put so much effort on it again unless it gets adopted by a relevant number of people (which, quite frankly, is really unlikely to happen). Being an open source project I obviously tried to put in place all the basic infrastructure (tests, code standards, repository, versioning, etc.) to make it easy for other people to work on improving it. Again, more precise informations are included in the official documentation.
Opinions
For me it has been a really good learning experience, especially considering the fact that it was a good scenario to use asynchronous code dealing with several parallel Http requests. As I still consider it a learning experience I would really love you (probably more experienced than me with Node.js) to give some opinions, critics, new ideas. I offer the comment box below for this sake… please don’t be too much indulgent :D





