There is one pattern that has been my secret sauce for AWS Lambda code for almost as long as I have been writing AWS Lambda code: the middleware pattern. If you have touched a modern web framework in the last decade (Express, Fastify, NestJS, Laravel, Django, Rails, FastAPI, … take your pick), you have almost certainly used this pattern, probably without even noticing. It is everywhere, and I love it!
I love it so much that, back in 2017, I started an open source project called Middy just to bring a fully fledged middleware engine to Node.js Lambdas. Today, Middy is widely used in the Node.js serverless ecosystem, and the pattern has been recognised as incredibly useful for keeping Lambda handlers clean and maintainable (huge props to the Middy community, and especially to Will Farrell, who has maintained and grown the project for years).
Recently I was building a rate limiter middleware for a Rust Lambda project at work, and I realised the generalised version of what I learned would make a great blog post. This is that post!
We will start by talking about the pattern itself and why it is such a good fit for Lambda. Then we will look at how it maps onto Rust by introducing tower, the generic middleware engine you can use with tokio and that is already sitting at the core of the AWS Lambda Rust runtime. To get ourselves familiar with tower’s interface, we will build a few small pieces of middleware to warm up, and finally put together a complete DynamoDB-backed IP rate limiter that you can use as is in your projects or as a template for your own custom middleware.
If you want to skip ahead to the code, the full working examples are live on GitHub.
The pattern that keeps on paying off
The “middleware pattern” is what happens when you take the Gang of Four Chain of Responsibility pattern and give it a friendlier name… and also a slightly more confusing one, because it risks collision with the older, broader systems-integration sense of “middleware”. Naming things is hard, so let’s accept that and let’s move on!
The idea is to create an abstraction that allows you to compose small, reusable units of logic around a core handler. It passes a request through an ordered chain of handlers, and each handler can choose to handle the request, transform it, or pass it along. A response that is ready to go out comes back up through the chain in reverse order. Each middleware gets a chance to influence the round trip.

In a Lambda function, a middleware is a thin wrapper around your core handler. In practice, each wrapper owns one cross-cutting concern: logging, request tracing, authentication, input validation, output shaping, CORS, error envelopes, rate limiting. You compose them in a chain (or in the case of tower, a stack), and the core handler stays laser focused on the actual business logic.
This matters a lot in Lambda for two reasons:
- Cross-cutting concerns are everywhere. A single service often has ten or fifteen Lambda handlers, and each one needs the same five or six things (parse JWT, decode body, enforce schema, emit structured logs, add response headers). Without middleware, the temptation is to copy-paste the same code into every handler. The day you need to change any of that, you’ll have to carefully update files all around the project.
- Handlers stay readable. When business logic is not buried under a few hundred lines of boilerplate, it becomes much easier to reason about, test, and review.
On top of that, committing to the pattern turns every cross-cutting concern into a small, self-contained unit of reusable, configurable, and testable logic. For example, you write a JWT verifier middleware once, unit-test it in isolation (no Lambda, no API Gateway, no mocks), ship it, and then just plug it into every handler that needs it. Multiply that across every cross-cutting concern in your stack and the maintainability and quality dividend becomes really hard to ignore.
That copy-paste fatigue around validation, error handling, and (de)serialisation is exactly what pushed me to start Middy. It now ships 30+ official general-purpose middleware, plus many more maintained by the community.
Does this pattern make sense in Rust?
Rust on Lambda is growing up fast. And for good reasons! If you want the long version of why Rust is such a great fit, check out my older post on why you should consider Rust for your Lambdas.
Switching to Rust does not make the cross-cutting concerns go away. Logging, auth, validation, rate limits: every Rust Lambda has them too, so the ergonomic problem of weaving them through every handler is the same problem we had in Node.js, and it calls for the same kind of solution.
But there is some pretty good news that makes Rust a bit unique among the other Lambda runtimes, and honestly the reason I wanted to write this post: the AWS Lambda Rust runtime already ships a middleware engine… it’s built in, and almost nobody uses it! Almost every Rust Lambda codebase I have reviewed in the last year bolts logging, auth, and validation directly into the handler, unaware that there is a proper composable middleware layer sitting one import away. To be fair, I have occasionally seen Rust Lambda codebases that work around this with clever helper functions, macros, or trait extensions, and some of those solutions are genuinely elegant. None of them quite match the convenience and composability of a real middleware stack, though. Once you see this pattern in action, you cannot unsee it, and that alone is reason enough to keep reading.
Enter tower: the middleware engine under the Rust Lambda runtime
If you have a superficial look at some code examples, you might come away thinking that middleware in Rust Lambda comes from lambda_http. That is not quite right, and it matters, because the pattern is more general than that.
tower is a generic middleware engine for the tokio async runtime. It is not specific to Lambda, HTTP, or AWS. Anything built on tokio can be composed with tower layers, which is why you will find tower underneath hyper, axum, tonic, reqwest and plenty of other ecosystem crates.
The official aws-lambda-rust-runtime is itself a tokio application, and it is carefully designed so that every Lambda handler is a tower Service. This is true at the base runtime level, not just at the lambda_http level. Your SQS consumer, your S3 event handler, your custom EventBridge Lambda: they are all tower services, and they can all be wrapped with tower middleware which can help you to manage cross-cutting concerns like logging, validation, error handling, and more in a consistent and reusable way.
The lambda_http crate is just a convenient wrapper that specialises the request and response types to HTTP. The middleware ergonomics come from tower, sitting one layer below. In this post we will focus on HTTP because it is the most common Lambda shape and also the one that arguably benefits most from this pattern, but everything here applies to non-HTTP events with minor adjustments.
The two core traits: Service and Layer
Tower is built around two traits. The first is Service. Conceptually, it is a function from a request to a future that resolves to a response, plus a readiness signal:
pub trait Service<Request> { type Response; type Error; type Future: Future<Output = Result<Self::Response, Self::Error>>;
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>>; fn call(&mut self, request: Request) -> Self::Future;}call is the interesting method: it does the work. poll_ready is a backpressure hook, used by services that need to buffer or throttle (a connection pool, for instance). For Lambda middleware you will almost always just delegate poll_ready to the inner service, because the real backpressure in Lambda is managed by the runtime itself.
The second trait is Layer. A layer is a factory that wraps a Service and produces a new Service:
pub trait Layer<S> { type Service; fn layer(&self, inner: S) -> Self::Service;}Most custom middleware is written as a pair: a XxxLayer that captures the configuration, and an XxxService<S> that is produced when the layer is applied to an inner service S.
This wrapping (a Service wrapping another inner Service) is the key to how composition works in tower. Each layer takes the service it wraps as a parameter (the S generic above) and returns a new service that wraps it. Apply two layers and you get a service that wraps a service that wraps a service. Apply three and the nesting goes one level deeper. That is why, even though we keep saying “chain” out of habit, what tower actually builds is a stack of nested services, with the original handler sitting at the bottom.
Layers are composed with ServiceBuilder, which stacks them onto a base service:
let service = ServiceBuilder::new() .layer(authentication) .layer(rate_limit) .service(handler);The stack applies outer-first on the request, outer-last on the response. So for this example the request hits authentication, then rate_limit, then handler; and the response goes back through rate_limit, then authentication.
A subtle but important point: in that snippet, handler itself has to be a Service too. A stack of tower layers eventually terminates in one innermost Service that actually does the work (the real business logic), and in our case that is the Lambda handler. There are generally two ways to produce that terminal service:
- Wrap a plain
async fnwithtower::service_fn. This is by far the most common choice, and what we will use throughout the rest of the post. - Write a full
impl Servicefor your handler type. Reach for this when you need fine-grained control overpoll_ready(backpressure on a connection pool, for instance) or when the handler owns typed mutable state that you want to manage explicitly.
For Lambda handlers, option 1 is nearly always enough.
Going back to that “stack of wrapped services” idea: it is much easier to picture once you draw it. Each layer is a box, and the box it wraps sits inside it. The request enters from the outside, falls through every box on the way down to the terminal handler at the bottom, and the response makes the trip back up in reverse:
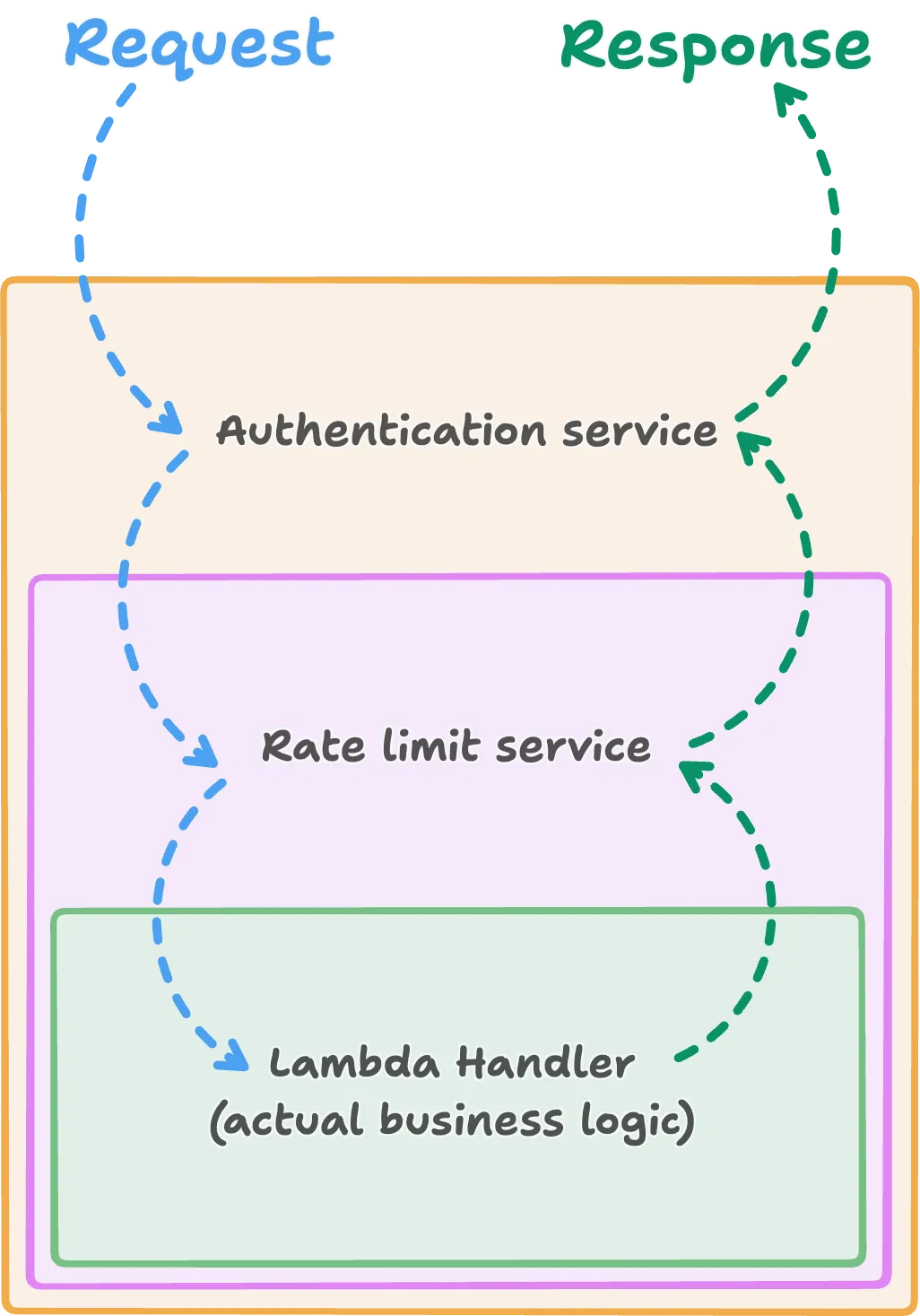
Each middleware gets a crack at the request on the way in, and another crack at the response on the way out. Authentication can reject unauthorised requests before they reach the rest of the stack, rate limiting can reject or throttle excessive traffic before it reaches the handler, and the handler can stay focused on the actual business logic. That is the whole mental model.
Now you see why it is called tower, right? 😏
A no-op middleware
Before doing anything useful, let us look at the shape of a tower middleware. This one passes every request and response through untouched:
use std::task::{Context, Poll};use lambda_http::tower::{Layer, Service};
#[derive(Clone)]pub struct NoopLayer;
impl<S> Layer<S> for NoopLayer { type Service = NoopService<S>; fn layer(&self, inner: S) -> Self::Service { NoopService { inner } }}
pub struct NoopService<S> { inner: S }
impl<S, R> Service<R> for NoopService<S>where S: Service<R>,{ type Response = S::Response; type Error = S::Error; type Future = S::Future;
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { self.inner.poll_ready(cx) }
fn call(&mut self, request: R) -> Self::Future { self.inner.call(request) }}There is more boilerplate than business logic here, but every line is earning its keep. NoopLayer is the configuration handle; its Layer impl wraps an inner service S to produce a NoopService<S>. The Service impl on NoopService<S> reuses the inner service’s Response, Error, and Future associated types verbatim, and both poll_ready and call just delegate. The interesting trick is that because we passed every type through unchanged, this middleware compiles against any tower service: HTTP, gRPC, custom event handlers, you name it. It is also completely useless on its own, but it is the skeleton we will flesh out in the next two examples to do something genuinely valuable.
NoopLayer is intentionally bare because the no-op has nothing to configure. When a real middleware needs settings (a sampling rate, a header name, a DynamoDB table name, a quota), those properties live on the Layer struct, with a constructor or builder to make instances ergonomic to set up; the matching Service then reads them out of an Arc (or whichever sharing strategy fits) on every call. We will see this play out properly when we build the rate-limit middleware later in the post. The mental model to take away from this section: Layer is where configuration and composition live; Service is where the business logic runs.
That is the whole shape. Everything else we do in this post is just more interesting implementations of call.
A logging middleware
The no-op middleware is the skeleton; now we are going to flesh it out. We will build a middleware that logs the HTTP method, path, and response status of every request that flows through it. It is the simplest piece of useful middleware imaginable, and yet it ends up walking us through most of the surprises you will hit when you start writing your own.
We will get there in three beats.
Logging the request: a one-line change
Logging the request before it reaches the inner service is trivially within reach. The no-op shape already gives us the request as an argument to call, so adding a log line is a one-line change in call (plus a couple of extra imports for tracing and the HTTP types):
13 collapsed lines
use std::task::{Context, Poll};
use http::Request;use lambda_http::tower::{Layer, Service};use lambda_http::{tracing, Body};
#[derive(Clone)]pub struct LogLayer;
impl<S> Layer<S> for LogLayer { type Service = LogService<S>; fn layer(&self, inner: S) -> Self::Service { LogService { inner } }}
pub struct LogService<S> { inner: S }
impl<S> Service<Request<Body>> for LogService<S>where S: Service<Request<Body>>,{ type Response = S::Response; type Error = S::Error; type Future = S::Future;
3 collapsed lines
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { self.inner.poll_ready(cx) }
fn call(&mut self, request: Request<Body>) -> Self::Future { tracing::info!( method = %request.method(), path = %request.uri().path(), "request" ); self.inner.call(request) }}Notice that type Future = S::Future is unchanged from the no-op. We have not touched the future at all. We log the method and path, then hand the unmodified request off to the inner service and return its future verbatim.
What about the response?
Pre-request work was easy. Now suppose we want the response status in the log line too. Status only exists once the inner service has resolved its future, so we need to do the work after the inner call returns. The naive translation of the no-op shape goes something like this:
13 collapsed lines
use std::task::{Context, Poll};
use http::{Request, Response};use lambda_http::tower::{Layer, Service};use lambda_http::{tracing, Body};
#[derive(Clone)]pub struct LogLayer;
impl<S> Layer<S> for LogLayer { type Service = LogService<S>; fn layer(&self, inner: S) -> Self::Service { LogService { inner } }}
pub struct LogService<S> { inner: S }
impl<S> Service<Request<Body>> for LogService<S>where S: Service<Request<Body>>,{ type Response = S::Response; type Error = S::Error; type Future = S::Future;
3 collapsed lines
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { self.inner.poll_ready(cx) }
fn call(&mut self, request: Request<Body>) -> Self::Future { let method = request.method().clone(); let path = request.uri().path().to_string(); let response = self.inner.call(request).await?; tracing::info!( method = %method, path = %path, status = %response.status(), "request" ); Ok(response) }}Unfortunately, this does not compile… and if you have seen your fair share of async Rust, the reason might not be too surprising:
error[E0728]: `await` is only allowed inside `async` functions and blocks --> examples/log_layer_broken.rs:106:49 |106 | let response = self.inner.call(request).await?; | ^^^^^ only allowed inside `async` functions and blocksThere it is!
Service::call is not an async fn; it returns a Self::Future. We cannot .await inside a non-async function body.
And, by the way, that is not the only thing wrong with this code. rustc short-circuits on the await failure and never gets a chance to report the second error, but the body of call also has a return-type mismatch: we kept type Future = S::Future, yet the body now tries to return a Result<_, _> instead of a future. Open the file in an editor running rust-analyzer and you can see the second error light up immediately, without having to wait for the compiler to recover from the first one:
expected `<S as Service<Request<Body>>>::Future`,found `Result<{unknown}, {unknown}>`[rust-analyzer E0308](The {unknown} placeholders show up because the body has not been fully type-checked yet, but the shape mismatch is clear: a Future was expected, a Result was produced.)
There is even a third problem lurking that the first compile error hides: we wrote response.status(), but the trait bound S: Service<Request<Body>> says nothing about what S::Response actually is. Without a Response = Response<Body> constraint, the compiler has no idea that the response has a .status() method at all. Once we fix the future shape, we will need to pin down the response type too.
The first two errors trace back to the same root cause: we cannot peek inside the inner future without producing a new Future type. As soon as the middleware needs to do post-response work, type Future has to change, and the trait bounds have to grow with it.
Wait, why can't I just write async fn call?
You may now be wondering: this is async code, surely it would be cleaner to make call itself async, and let the compiler figure out the future type for us? Welcome to the rabbit hole.
Rust 1.75 stabilised async functions in traits (AFIT), so you might reasonably expect to be able to write:
impl<S> Service<Req> for MyMiddleware<S> { async fn call(&mut self, req: Req) -> Result<Response, Error> { ... }}You cannot, and it is not your fault. The tower Service trait predates AFIT and has a specific shape that needs a nameable Future associated type with Send + 'static bounds. Two limitations of AFIT get in the way:
- The future returned by an
async fnin a trait is anonymous, so you cannot name it to satisfytype Future = .... - AFIT does not yet offer a stable way to add
Send + 'staticbounds to that returned future without reaching for unstable features or thetrait-variantcrate, and the tower ecosystem really wantsFuture: Send + 'static.
So every tower middleware falls back to one of these patterns:
- Use
tower::service_fnto wrap a plainasync fn. This is what you do for the terminal handler (our Lambda function) in the vast majority of cases, and it is exactly what we do later when we wire up our rate limit middleware. - For a real stateful
Serviceimpl (the middleware we are about to write below), declaretype Future = Pin<Box<dyn Future<Output = ...> + Send>>and writecallasBox::pin(async move { ... }). You are not really hand-rollingpoll, you are just boxing anasyncblock. The one heap allocation per request costs nothing worth measuring in Lambda.
There is ongoing work on an async-native Service trait, but until it lands, Box::pin(async move { … }) is the idiomatic shape, and that is exactly what we will use to fix our currently broken logging middleware.
The fix: Box::pin and async move
The fix is to change type Future so it is no longer S::Future, then wrap the post-response work in an async block we own:
use std::future::Future;use std::pin::Pin;use std::task::{Context, Poll};
use http::{Request, Response};use lambda_http::tower::{Layer, Service};use lambda_http::{tracing, Body};
7 collapsed lines
#[derive(Clone)]pub struct LogLayer;
impl<S> Layer<S> for LogLayer { type Service = LogService<S>; fn layer(&self, inner: S) -> Self::Service { LogService { inner } }}
pub struct LogService<S> { inner: S }
impl<S> Service<Request<Body>> for LogService<S>where S: Service<Request<Body>, Response = Response<Body>> + Send + 'static, S::Future: Send, S::Error: Send,{ type Response = Response<Body>; type Error = S::Error; type Future = Pin<Box<dyn Future<Output = Result<Self::Response, Self::Error>> + Send>>;
3 collapsed lines
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { self.inner.poll_ready(cx) }
fn call(&mut self, request: Request<Body>) -> Self::Future { let method = request.method().clone(); let path = request.uri().path().to_string(); let fut = self.inner.call(request); Box::pin(async move { let response = fut.await?; tracing::info!(method = %method, path = %path, status = %response.status(), "request"); Ok(response) }) }}A few things worth pointing out:
type Futureis now a boxed trait object:Pin<Box<dyn Future<Output = ...> + Send>>. Thedynis dynamic dispatch: the concrete future produced by theasync moveblock is opaque to the outside world, and method calls on it go through a vtable. That is what lets us hand back a singlePin<Box<…>>type regardless of which inner service we wrap. The cost is one heap allocation per request, which is probably negligible in the context of AWS Lambda.- The
async move { … }block is where post-response middleware work happens. By wrapping the inner future inside anasyncblock we get back the right to.awaitit, exactly as we wanted in the broken version. The whole block evaluates to an anonymousFuture, andBox::pinpins and boxes it so its type matchesSelf::Future. - The trait bounds grew.
S: Service<...> + Send + 'static, plusS::Future: SendandS::Error: Send. Boxed trait-object futures needSend + 'static, and the inner service has to play along. These look intimidating the first time you see them, but they are boilerplate. Copy-paste, adjust the types, move on. - Pre-await is request work, post-await is response work. We clone
methodandpathbeforeself.inner.call(...), becausecallconsumes the request. Thetracing::info!fires afterfut.await?, because the status only exists then. This request-then-response framing is the single most useful mental model for tower middleware: code above theawaitinspects or transforms the request, code below it inspects or transforms the response.
What if Box::pin(async move { … }) weren't on the menu?
Box::pin(async move { … }) is so ergonomic it can hide what is actually happening. Under the hood, the async block is the compiler’s desugaring of an anonymous state machine that implements Future, and Box::pin boxes-and-pins that anonymous future so its concrete type disappears behind the dyn in type Future = Pin<Box<dyn Future<…>>>.
But what if the language did not give us async blocks at all? Could we still ship this middleware? Yes, by writing the Future ourselves. This is also what some tower-using crates do, especially older ones, and it is worth seeing once so the boxed-async shape feels less magical.
use std::future::Future;use std::pin::Pin;use std::task::{Context, Poll};
use http::{Method, Request, Response};use lambda_http::tower::{Layer, Service};use lambda_http::{tracing, Body};use pin_project_lite::pin_project;
7 collapsed lines
#[derive(Clone)]pub struct LogLayer;
impl<S> Layer<S> for LogLayer { type Service = LogService<S>; fn layer(&self, inner: S) -> Self::Service { LogService { inner } }}
pub struct LogService<S> { inner: S }
impl<S> Service<Request<Body>> for LogService<S>where S: Service<Request<Body>, Response = Response<Body>>,{ type Response = Response<Body>; type Error = S::Error; type Future = LogFuture<S::Future>;
3 collapsed lines
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { self.inner.poll_ready(cx) }
fn call(&mut self, request: Request<Body>) -> Self::Future { let method = request.method().clone(); let path = request.uri().path().to_string(); LogFuture { method, path, inner: self.inner.call(request), } }}
pin_project! { pub struct LogFuture<F> { method: Method, path: String, #[pin] inner: F, }}
impl<F, E> Future for LogFuture<F>where F: Future<Output = Result<Response<Body>, E>>,{ type Output = Result<Response<Body>, E>;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let this = self.project(); match this.inner.poll(cx) { Poll::Pending => Poll::Pending, Poll::Ready(Ok(response)) => { tracing::info!( method = %this.method, path = %this.path, status = %response.status(), "request" ); Poll::Ready(Ok(response)) } Poll::Ready(Err(e)) => Poll::Ready(Err(e)), } }}What did we trade?
- Up: about thirty extra lines, an extra struct, plus a
pin-project-litedependency. The struct holds the pieces we need acrossawaitpoints (method, path, the inner future). TheFutureimpl on it polls the inner future and only emits the log line when the inner future resolves withOk. - Down: zero heap allocations per request, because
LogFuture<F>is a concrete type sized at compile time. In Lambda, that is irrelevant. In a tight loop on a busy server, it can matter.
Box::pin(async move { … }) is doing exactly this work for you, ergonomically. The compiler builds an anonymous state machine equivalent to LogFuture from the body of the async block, and Box::pin puts it on the heap so its size is known at the trait-object boundary. You give up one allocation per call to skip writing the boilerplate by hand.
A header-injecting middleware
The logger middleware looked at the response on its way out (we read the response status using .status()) but did not change it. In the next snippet we will learn how to actually modify the response instance by adding a PoweredByLayer that attaches an x-powered-by: rust header to every outgoing response.
Who doesn’t like to brag about Rust, right? 😇
So, we are not going to touch the request or the body, but just inject a new response header. It’s a trivial example, but it represents quite well the kind of work you actually do in real middleware (CORS headers, security headers, request-id tagging, response-shape envelopes), and the shape of the code should look familiar after the logger fix:
14 collapsed lines
use http::{HeaderValue, Response};use lambda_http::tower::{Layer, Service};use lambda_http::Body;use std::future::Future;use std::pin::Pin;use std::task::{Context, Poll};
#[derive(Clone)]pub struct PoweredByLayer;
impl<S> Layer<S> for PoweredByLayer { type Service = PoweredByService<S>; fn layer(&self, inner: S) -> Self::Service { PoweredByService { inner } }}
pub struct PoweredByService<S> { inner: S }
impl<S> Service<http::Request<Body>> for PoweredByService<S>where S: Service<http::Request<Body>, Response = Response<Body>> + Send + 'static, S::Future: Send,{7 collapsed lines
type Response = Response<Body>; type Error = S::Error; type Future = Pin<Box<dyn Future<Output = Result<Self::Response, Self::Error>> + Send>>;
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { self.inner.poll_ready(cx) }
fn call(&mut self, request: http::Request<Body>) -> Self::Future { let fut = self.inner.call(request); Box::pin(async move { let mut response = fut.await?; response .headers_mut() .insert("x-powered-by", HeaderValue::from_static("rust")); Ok(response) }) }}Same shape, slightly different call body. There is still a bit of boilerplate, but hopefully, at this point, it is becoming muscle memory.
Short-circuits and error flow in tower middleware
Before we move on to testing, there is one piece of the middleware playbook we have not exercised yet: every call implementation we have seen so far has dutifully forwarded the request down to the inner service, and used ? so that any errors travel straight back up the stack. The happy path.
What if a middleware wants to short-circuit a request and skip the inner service entirely? And, while we are at it, what about the case where the inner service does run and fails on us (i.e. it produces an Err)?
Skipping the inner service comes up more often than you might think. Imagine a validator middleware: if the incoming request fails its checks, there is no point in calling the inner service at all. You are going to return an error to the client either way, so why pay for the business logic? In fact, the whole point of the validator is to protect (i.e. not run) the main business logic when the request is invalid.
Tower has a clean answer for these use cases, and they turn out to be two sides of the same Result coin (the Ok path and the Err path). We will cover short-circuiting first as the umbrella mechanism, then come back to inner-service failures as a special case. Both are worth understanding before we wire up the rate limiter.
Short-circuiting and the up/down trip
Short-circuiting means a middleware decides to return a response (or an Err) before it calls the inner service. The two arrow directions in our stack of services are just the two halves of a function call: calling inner.call(req) is what makes the arrow go down into the next layer, and returning from call is what makes the arrow come back up. A short-circuiting middleware never makes that downward call from itself onward, which is why the request never reaches the layers below.
A nice side effect of that: the work below a short-circuit is not paid for in any meaningful sense. Depending on how the middleware is written, the inner future may still be constructed (because the service holds a handle to call into the next layer), but it is never .await-ed. Everything that lives behind that .await (the handler body, any downstream HTTP calls, the DynamoDB read in the next middleware) simply does not run. Latency, network round-trips, billed work: all skipped.
The picture is the same nested-box mental model from earlier, with one extra arrow showing what happens when something short-circuits partway down the stack:
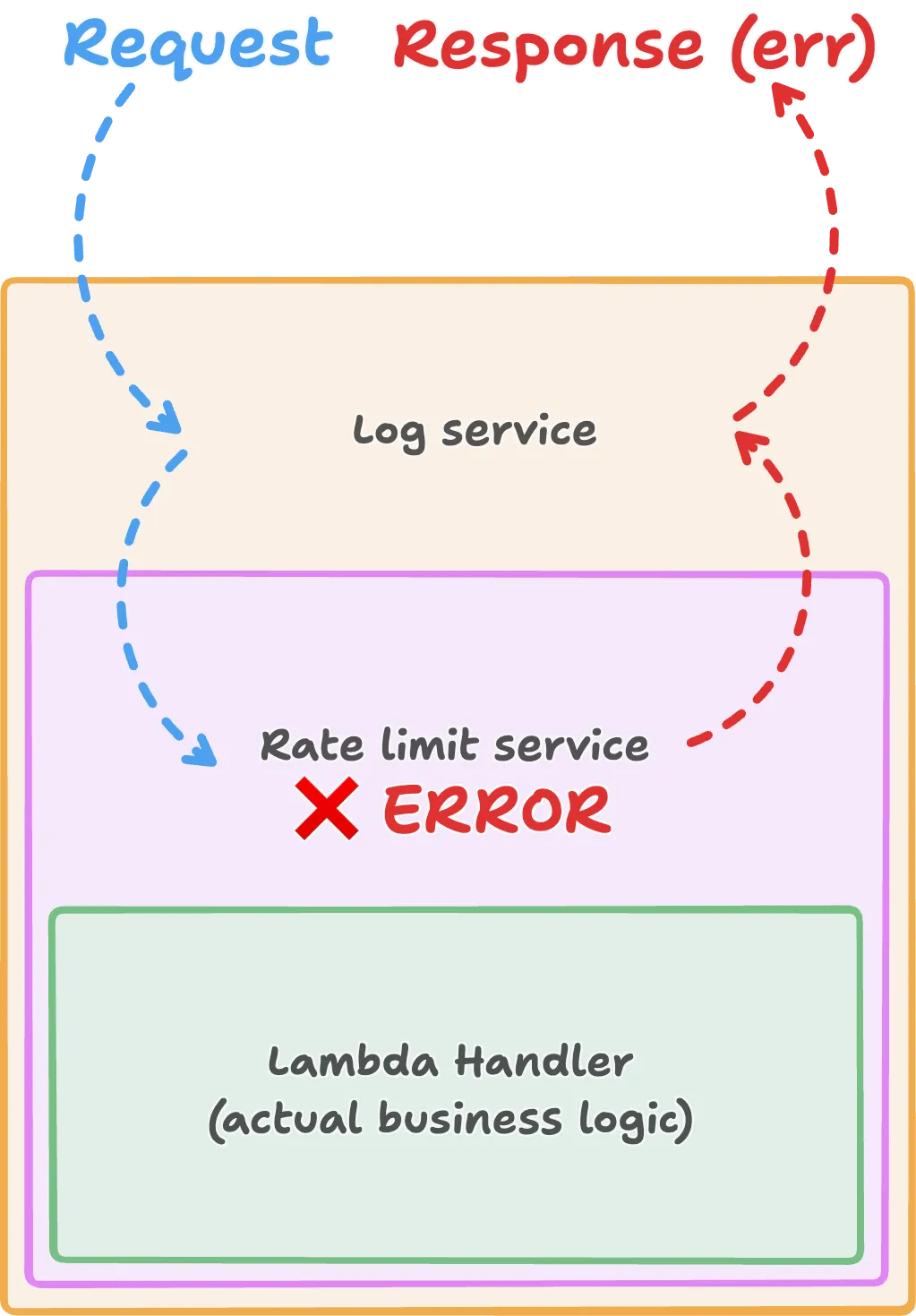
In the diagram the rate-limit service rejects the request, so the Lambda handler never runs. The response (an error here, but it could just as easily have been an Ok carrying a 429) only travels back up through the layers it had already entered. Layers above the short-circuit point still see the request go in and the response come back out; any further layers below the rate limiter would be skipped in exactly the same way as the handler.
Order matters
Following directly from the picture: the order of layers in the stack matters. Whatever you put on the outside runs on every request, no matter what happens further down. Whatever you put on the inside only runs when the layers above it let the request through.
That gives you a cheap heuristic for choosing where each piece of middleware goes:
- Outside (always runs) is the natural home for cross-cutting concerns you want on every request: logging, tracing, CORS, response-shape envelopes, structured error mapping, and any “catch every remaining error and turn it into a 500” safety net. Put a safety net on the inside and it will only see errors from its own handler, which is too late to help.
- Inside (may be skipped) is the natural home for short-circuiting work that can decide to bail out early: authentication, rate limiting, request validation.
In our running example, because the log service sits outside the rate-limit service, every rate-limited 429 response still gets logged on its way out. Swap the order and you would lose that visibility.
In tower terms: each layer can intercept the request and the response (or error) from anything below it, never from above. That direction is one-way.
Errors are not special: they ride on Result
So far we have talked about a middleware choosing to short-circuit. What about the case where an inner service fails?
The trick is to notice that there is nothing special about errors in tower. Service::call returns a future that resolves to Result<Response, Error>. Returning Err(...) and returning Ok(...) are both perfectly valid completion states; they are just two halves of the same value space. When an inner service hands back Err, that Err arrives at the wrapping layer as the result of an .await, and the wrapping layer then has the same three options it would have for any Result:
Propagate it untouched with
?. The log and header-injecting middleware we wrote earlier both do this:let response = self.inner.call(req).await?;The
?hands the error off to the next layer up the stack, just like it would in any plain synchronous function. From there, each enclosing layer can look at it, transform it, or recover from it.Intercept and transform it, for example to log it or to map one error type into another. Tower also exposes
ServiceExt::map_errif you want this as a small wrapper layer.Recover by handing back
Ok(...)of a synthetic response. This is short-circuiting performed reactively: instead of letting the failure propagate, the middleware picks a response and returns a successfulResult, so no outer layer ever sees the error:match self.inner.call(req).await {Ok(response) => Ok(response),Err(_) => Ok(Response::builder().status(503).header("content-type", "application/json").body(Body::from(r#"{"error":"service unavailable"}"#)).unwrap()),}From the perspective of any outer layer, this service succeeded.
The HTTP rule of thumb
In an HTTP-shaped middleware (which is what lambda_http gives us), the rule that has served me well is:
- Return
Ok(response)for anything you want the client to see, even when the response is a 401, 403, 429, or 500. The status code carries the semantics;Okjust says “this service produced a response”. - Reserve
Err(...)for transport-level failures that you genuinely expect the runtime above you to translate, and only when there is an outer layer prepared to do that translation.
The failure mode if you ignore this is worth keeping in mind. If an Err escapes all the way up to lambda_http::run, the Lambda runtime treats it as an invocation error. API Gateway sees the failed invocation and answers the client with a generic 502 Bad Gateway. The structured 503 (or 401, or 429) you carefully designed never reaches the client. Avoiding that confusion is the entire reason the rule exists.
What each layer gets to do
Pulling it all together: every layer that is actually called has four moves available, two on the way in and two on the way out.
On the way in, before inner.call(req):
- Inspect or transform the request before passing it down.
- Short-circuit by returning a response (or an
Err) without calling the inner service at all.
On the way out, after inner.call(req).await:
- Inspect or transform the response before passing it up.
- Recover from an inner-service failure by returning
Ok(synthetic_response)instead of letting theErrpropagate.
That is the entire toolkit. Almost every useful middleware is some combination of those four moves on top of the no-op shape.
Back to the rate limiter
So how do we apply all this to our rate limiter? Concretely, when a client trips the limit (or when DynamoDB is unreachable), we have a choice between two designs:
- Return a descriptive
Err(something likeRateLimitError::Exceeded { retry_after, ... }) and trust an outer layer in the stack to translate it into an HTTP response. This is the most “general purpose” version of the middleware: anyone plugging it in keeps full control over what their 429 (or 503) ultimately looks like. The cost is that every consumer has to actually write that translation layer, which is real work and one more thing to remember. - Short-circuit with a pre-baked
Ok(response)containing a sensible 429 (or 503). Anyone who drops the middleware into aServiceBuildergets a working rate limiter with no extra code. The cost is the response shape is baked in, which is awkward the first time someone needs to add a custom header or change the body.
We will go with option 2. A drop-in middleware that just works is worth a lot in practice, especially for the kind of “I want to add rate limiting to this Lambda before lunch” scenario this post is chasing. We will start with a minimal version that returns fixed default responses (so the focus stays on the rate-limit logic itself), and then revisit the customisation question in a second pass with a small trick that lets callers tweak those responses without forking the crate (and without having to add an additional service).
Testing without Lambda
One last piece of the puzzle. The tower crate exposes a useful trait called ServiceExt that adds a .oneshot(request) helper. It lets you call a service once in a test, without standing up any runtime or mock infrastructure:
use lambda_http::tower::ServiceExt;
let response = my_service.oneshot(request).await.unwrap();assert_eq!(response.status(), StatusCode::OK);It is a pretty neat utility that I only discovered recently, and we will lean on it heavily in the rate limiter tests.
A real world example: DynamoDB-backed IP rate limiting
Time to build something useful. We are going to write a middleware that enforces a per-IP rate limit using a DynamoDB atomic counter, and it will emit the standard response headers so clients can self-pace.
Why not just use API Gateway usage plans?
Good question. For many use cases, API Gateway usage plans are fine. But they have key limitations regarding observability and flexibility. Building your own middleware gives you the shape of limits that fits your business logic, and more importantly, it allows you to tell your clients exactly how much quota they have left (which is exactly what I wanted to achieve myself in my latest project).
- If you are on HTTP API (v2), usage plans do not exist. Period. They are a REST API (v1) feature only.
- Even on REST, usage plans are invisible to clients. API Gateway will reject you with a 429 once you are over the limit, but it will not tell you how many requests you have left or when the counter resets. There are no
X-RateLimit-*response headers (or any other quota hint). Compare that with GitHub’s REST API, where every response carriesX-RateLimit-Limit,X-RateLimit-Remaining, andX-RateLimit-Reset. Modern clients use those headers to pace themselves gracefully, and your clients cannot do that when you only hand them a 429 after the fact. - API keys must exist before the first request. This is awkward for dynamic user bases, and the hard cap of 10,000 keys per account per region makes it unworkable for consumer-scale apps.
- Quota windows are coarse and best-effort. Usage plan periods are
DAY,WEEK, orMONTH; if your business logic wants a 15-minute window, usage plans will not help you. Even within those periods, AWS documents the throttling and quota numbers as best-effort targets, not exact ceilings.
For a deeper tour of this tradeoff space (including WAF rate-based rules and CloudFront Functions tricks), Warren Parad has a great write-up: Exceeding AWS rate-limiting, CloudFront, usage plans.
What we are building
The requirements:
- Count the incoming requests by client IP. This keeps the tutorial simple; real apps often prefer a stable user ID (for example, from a JWT claim), and swapping in a different key-extraction function is a one-line change once the rest of the middleware is in place.
- Fixed window, configurable via a
window_durationparameter (astd::time::Duration). We default to 15 minutes because it is a common choice. - Atomic counter in DynamoDB, with TTL-based cleanup. No cron, no scans.
- Standard(ish) response headers on every successful response:
X-RateLimit-Limit,X-RateLimit-Remaining,X-RateLimit-Reset. These follow the GitHub / Twitter convention, withResetas a Unix epoch timestamp. The IETF also has a draft for this, but as of writing it has churned through several incompatible shapes (the latest editor’s draft uses combinedRateLimitandRateLimit-Policyfields with a delay-second reset). Pick whichever fits your clients; switching is a one-spot change in the response helper below. - A plain JSON
429body with aRetry-Afterheader when the limit is hit.
One honest caveat before we start. We are using a fixed-window counter, which is the simplest thing that could possibly work. It has one well-known downside, and you might be curious about how it compares to the more sophisticated alternatives.
Fixed window vs token bucket vs sliding window: what we are giving up
Picture a 60-second window with a 100-request limit. A motivated client can fire all 100 requests in the last second of one window and another 100 requests in the first second of the next window: 200 requests in two seconds, even though the configured rate is 100 per minute. The window edge is a free reset, and a client that knows your window length can ride right over it. This is sometimes called the window boundary burst, and it is the textbook reason people move on from fixed windows in production-grade rate limiters.
The two standard fixes both eliminate the boundary, at a cost:
- Token bucket: every key has a “bucket” of tokens that refills continuously at the configured rate; each request consumes one token, and requests are denied when the bucket is empty. There is no window edge to exploit, and short bursts (up to the bucket size) are still allowed, which is usually what you actually want. The DynamoDB shape costs you a read-modify-write per request: you fetch the current token count and the timestamp of the last refill, recompute, and conditionally write back. That is one extra round trip and a more elaborate failure mode (lost update under conflict) than a single
UpdateItemADD. - Sliding window (in the rate-limiting sense, see Cloudflare’s Counting your way to better rate limiting for a friendly walkthrough): keep counters for the current and previous window and weight the previous one by the fraction of it that still falls inside the trailing 60 seconds. It is more accurate than the fixed window without becoming as expensive as a true per-request log, but it still costs you two reads per request instead of one atomic increment.
The middleware shape we end up with does not change with any of these: the Layer and Service plumbing is identical, only the arithmetic and the storage round-trips inside the store implementation move. For this post we stick to the fixed window mostly because it keeps the DynamoDB schema minimal and easy to follow (one row per IP per window, nothing to clean up beyond TTL), which keeps the focus on middleware mechanics rather than counter design. Swapping the algorithm is left as a follow-up.
Building the rate limit middleware
Time to wire it all up. The code lives in the companion repo; this section walks through the two files that make up the middleware itself: src/ip_extractor.rs (a helper module that pulls the client IP out of an incoming request) and src/rate_limit.rs (the Layer + Service pair that does the actual rate limiting). There is also a simple deployable hello-world Lambda that plugs in the rate limiter, and a SAM template you can use to deploy the whole thing in one go, more on those later.
One quick note on dependencies before we dive in (the full Cargo.toml is in the repo). We are not pulling in tower directly: lambda_http re-exports the bits we need under lambda_http::tower::* (Layer, Service, ServiceBuilder, ServiceExt, service_fn, and so on). That guarantees we always end up with the exact tower version the runtime is built against, avoiding a whole class of trait-mismatch headaches.
Extracting the client IP
First we need to know who is making the request. We are deploying behind API Gateway (HTTP API v2, in our SAM template), and on that integration AWS hands us the source IP straight on the event payload, in the request context. The Lambda runtime fills it from the actual TCP connection, so HTTP clients cannot forge it.
REST API (v1) places it at requestContext.identity.sourceIp; HTTP API (v2) places it at requestContext.http.sourceIp. A small match covers both:
use std::net::IpAddr;use std::str::FromStr;
use lambda_http::request::RequestContext;use lambda_http::{Request, RequestExt};
pub fn extract_ip(request: &Request) -> Option<IpAddr> { match request.request_context_ref()? { RequestContext::ApiGatewayV1(ctx) => ctx .identity .source_ip .as_deref() .and_then(|ip| IpAddr::from_str(ip).ok()), RequestContext::ApiGatewayV2(ctx) => ctx .http .source_ip .as_deref() .and_then(|ip| IpAddr::from_str(ip).ok()), _ => None, }}If neither variant matches (for example, an event from a different integration), we return None and let the middleware fail open rather than trying to make something up.
The rate limit middleware
And finally, the main event! I will show the file in three passes so we can talk about each piece.
The config and the layer
use std::sync::Arc;use std::time::Duration;
use lambda_http::tower::Layer;
#[derive(Clone)]pub struct RateLimitConfig { pub table_name: String, pub max_requests: u32, pub window_duration: Duration,}
#[derive(Clone)]pub struct RateLimitLayer { config: Arc<RateLimitConfig>, client: aws_sdk_dynamodb::Client,}
impl RateLimitLayer { pub fn new(config: RateLimitConfig, client: aws_sdk_dynamodb::Client) -> Self { Self { config: Arc::new(config), client, } }}
impl<S> Layer<S> for RateLimitLayer { type Service = RateLimitService<S>;
fn layer(&self, inner: S) -> Self::Service { let store: Arc<dyn RateLimitStore> = Arc::new(DynamoDbRateLimitStore { client: self.client.clone(), }); RateLimitService { inner, store, config: Arc::clone(&self.config), } }}A few things worth pointing out:
RateLimitConfigholds the plain data (table name, limits). Wrapping it inArconce inRateLimitLayer::newmeans every subsequent.clone()(and there are a few, because tower sometimes clones services for concurrent calls) is just a refcount bump.- The DynamoDB
Clientalready wraps its internals in anArc, so a plain.clone()is cheap and we do not need to wrap it again. - The
Layer::layerimpl is where we construct the innerService. Notice we also create aRateLimitStorehere; we will get to why it is a trait in a moment.
This is exactly the Layer is the public configuration surface, Service is the implementation split we mentioned all the way back when we walked through the no-op middleware. RateLimitLayer is what a caller touches: the RateLimitConfig, the DynamoDB client, and the new(...) constructor are the API. Everything inside RateLimitService is implementation detail that callers neither see nor care about, which is why it lives one layer down. With that in mind, on to the implementation.
The service
10 collapsed lines
use std::future::Future;use std::pin::Pin;use std::task::{Context, Poll};use std::time::{SystemTime, UNIX_EPOCH};
use http::{Request, Response};use lambda_http::tower::Service;use lambda_http::{tracing, Body};
use crate::ip_extractor::extract_ip;
pub struct RateLimitService<S> { inner: S, store: Arc<dyn RateLimitStore>, config: Arc<RateLimitConfig>,}
impl<S> Service<Request<Body>> for RateLimitService<S>where S: Service<Request<Body>, Response = Response<Body>> + Send + 'static, S::Future: Send, S::Error: Send,{ type Response = Response<Body>; type Error = S::Error; type Future = Pin<Box<dyn Future<Output = Result<Self::Response, Self::Error>> + Send>>;
3 collapsed lines
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { self.inner.poll_ready(cx) }
fn call(&mut self, request: Request<Body>) -> Self::Future { let config = Arc::clone(&self.config); let store = Arc::clone(&self.store);
let ip = extract_ip(&request); // 1 let inner_future = self.inner.call(request);
Box::pin(async move { let Some(ip) = ip else { // 2 tracing::warn!("rate_limit: could not determine client IP, allowing request"); return inner_future.await; };
let now = current_epoch_secs(); // 3 let window = config.window_duration.as_secs().max(1); let bucket = now / window; let reset_at = bucket.saturating_add(1).saturating_mul(window); let seconds_until_reset = reset_at.saturating_sub(now);
let pk = format!("{ip}#{bucket}"); let ttl = reset_at.saturating_add(window); // 4
let count = match store.increment_and_get(&config.table_name, &pk, ttl).await { Ok(c) => c, Err(e) => { // 5 tracing::error!(ip = %ip, window = bucket, error = %e, "rate_limit: DynamoDB error"); return Ok(build_unavailable_response()); } };
let limit = config.max_requests; tracing::debug!(ip = %ip, window = bucket, count, limit, "rate_limit decision"); if count > limit { // 6 return Ok(build_over_limit_response( limit, reset_at, seconds_until_reset, )); }
let mut response = inner_future.await?; // 7 let remaining = limit.saturating_sub(count); append_rate_limit_headers(response.headers_mut(), limit, remaining, reset_at); Ok(response) }) }}
6 collapsed lines
fn current_epoch_secs() -> u64 { SystemTime::now() .duration_since(UNIX_EPOCH) .map(|d| d.as_secs()) .unwrap_or(0)}A few things worth unpacking:
- We extract the IP before calling
inner.call(request). Same pattern as the logging middleware: oncecallis invoked, the request has moved. If you try to read headers after, the compiler will stop you. - Fail open on missing IP. No IP means we cannot key the counter, so the best we can do is log a warning and pass the request straight through to the inner service. The alternative (rejecting every unidentifiable request) would lock out legitimate traffic the moment a misbehaving proxy drops a header, which is rarely what you want for a rate limiter.
- The window bucket is one line of arithmetic:
bucket = now / window, wherewindowiswindow_duration.as_secs()(clamped to at least one second so a misconfigured zero-length window cannot divide by zero). Every request that lands within a window maps to the same bucket integer, and the reset time is(bucket + 1) * window. This is why the PK format is"{ip}#{bucket}": every bucket gets its own row, and rows for old buckets age out via TTL.saturating_add,saturating_mul,saturating_sub. These are Rust’s “clamp at the edges of the type” arithmetic methods on integers. A plainbucket + 1would panic in debug builds and silently wrap to0in release builds ifbucketsomehow reachedu64::MAX; saturating arithmetic instead caps the result atu64::MAX(or0for the subtraction) and keeps going. With au64epoch, overflow is not a realistic concern in this lifetime, but usingsaturating_*for arithmetic that touches user-controlled or clock-derived values is a tidy default that costs nothing and rules out a whole class of “what if the input is weird” footguns. The same reasoning applies to thelimit.saturating_sub(count)later on, which keepsremainingat0if the counter ever overshoots. - TTL is set to
reset_at + window, one window past the reset. Why one window past, and not exactlyreset_at? It protects us from a boundary-write race: a request whosenowfalls in the last second of the bucket may not actually reach DynamoDB until afterreset_at(network latency between the Lambda and DynamoDB, SDK retries on a transient hiccup). With one window of headroom, the row is still alive when that late write lands, so the counter is updated correctly instead of theADDresurrecting a fresh row withcalls = 1. - Fail closed on DynamoDB errors. A counter-store outage is the opposite of the missing-IP case: we deliberately do not want to silently let traffic past while the limiter is blind, so we hand back a 503. This is the “bail out with
Ok(response)” pattern from the short-circuits and error flow section above; we never returnErr(...)because that would surface as a 502 invocation error and the client would lose the structured 503. - Over the limit: short-circuit with a 429. Once we have the updated
countfrom the store, the decision is justcount > limit. If it is, we never touch the inner service: we build a pre-baked 429 response withRetry-Afterand the standardX-RateLimit-*headers (we will see the helper in the next section) and return it asOk(...). This is the same short-circuit pattern as the 503, just driven by quota rather than infrastructure failure. Theinner_futurewe constructed at the top ofcallis simply dropped without being awaited, so the handler body never runs. - Under the limit: forward and stamp. The happy path. We
.awaitthe inner future, propagate any handler error with?, computeremaining = limit - count, and callappend_rate_limit_headersto attachX-RateLimit-Limit,X-RateLimit-Remaining, andX-RateLimit-Resetto the outgoing response. The handler itself does not need to know the rate limiter exists; it just sees a request go in and a response come out, with the limiter quietly counting and stamping at the edges.
The response helpers and the store
The Service::call body we just walked through called into three helpers we have not actually defined yet: append_rate_limit_headers (the header-stamping function used on the happy path), build_over_limit_response (the pre-baked 429), and build_unavailable_response (the pre-baked 503). It also leaned on a RateLimitStore trait whose increment_and_get does the atomic DynamoDB work. Time to fill in those last pieces.
use http::HeaderValue;use serde::Serialize;
fn append_rate_limit_headers(headers: &mut http::HeaderMap, limit: u32, remaining: u32, reset_at: u64) { if let Ok(v) = HeaderValue::from_str(&limit.to_string()) { headers.insert("X-RateLimit-Limit", v); } if let Ok(v) = HeaderValue::from_str(&remaining.to_string()) { headers.insert("X-RateLimit-Remaining", v); } if let Ok(v) = HeaderValue::from_str(&reset_at.to_string()) { headers.insert("X-RateLimit-Reset", v); }}
#[derive(Serialize)]struct RateLimitErrorBody<'a> { error: &'a str, retry_after: u64,}
fn build_over_limit_response( limit: u32, reset_at: u64, seconds_until_reset: u64,) -> Response<Body> { let body = serde_json::to_string(&RateLimitErrorBody { error: "rate limit exceeded", retry_after: seconds_until_reset, }) .unwrap_or_else(|_| r#"{"error":"rate limit exceeded"}"#.to_string());
Response::builder() .status(429) .header("content-type", "application/json") .header("Retry-After", seconds_until_reset.to_string()) .header("X-RateLimit-Limit", limit.to_string()) .header("X-RateLimit-Remaining", "0") .header("X-RateLimit-Reset", reset_at.to_string()) .body(body.into()) .expect("valid 429 response")}
fn build_unavailable_response() -> Response<Body> { Response::builder() .status(503) .header("content-type", "application/json") .body(r#"{"error":"service unavailable"}"#.into()) .expect("valid 503 response")}The 429 body is deliberately simple: just a short JSON payload with error and retry_after. The HTTP status code plus the standard headers already carry all the semantics that matter. The 503 fallback is even shorter: when the counter store is unreachable, the safest thing we can do is refuse traffic with a generic “service unavailable”, which is exactly what 503 means.
Now the DynamoDB store. I like to put the storage logic behind a small trait, because it makes the service trivial to unit-test with an in-memory mock:
#[async_trait::async_trait]trait RateLimitStore: Send + Sync { async fn increment_and_get( &self, table_name: &str, pk: &str, ttl: u64, ) -> Result<u32, RateLimitStoreError>;}
#[derive(Debug, thiserror::Error)]enum RateLimitStoreError { #[error("DynamoDB error: {0}")] DynamoDb(String),}
struct DynamoDbRateLimitStore { client: aws_sdk_dynamodb::Client,}
#[async_trait::async_trait]impl RateLimitStore for DynamoDbRateLimitStore { async fn increment_and_get( &self, table_name: &str, pk: &str, ttl: u64, ) -> Result<u32, RateLimitStoreError> { let result = self .client .update_item() .table_name(table_name) .key("pk", aws_sdk_dynamodb::types::AttributeValue::S(pk.to_string())) .update_expression("ADD #calls :one SET #ttl = if_not_exists(#ttl, :ttl_val)") .expression_attribute_names("#calls", "calls") .expression_attribute_names("#ttl", "ttl") .expression_attribute_values(":one", aws_sdk_dynamodb::types::AttributeValue::N("1".to_string())) .expression_attribute_values(":ttl_val", aws_sdk_dynamodb::types::AttributeValue::N(ttl.to_string())) .return_values(aws_sdk_dynamodb::types::ReturnValue::UpdatedNew) .send() .await .map_err(|e| RateLimitStoreError::DynamoDb(e.to_string()))?;
let count = result .attributes() .and_then(|attrs| attrs.get("calls")) .and_then(|v| v.as_n().ok()) .and_then(|n| n.parse::<u32>().ok()) .ok_or_else(|| { RateLimitStoreError::DynamoDb( "missing or invalid 'calls' attribute in UpdateItem response".to_string(), ) })?;
Ok(count) }}The DynamoDB update expression is the important part:
ADD #calls :one SET #ttl = if_not_exists(#ttl, :ttl_val)ADD #calls :one is an atomic increment; if the attribute does not exist yet, DynamoDB creates it with the initial value (effectively 0 + 1). SET #ttl = if_not_exists(#ttl, :ttl_val) stamps the row with a TTL only on first write, so repeat calls in the same bucket do not keep rewriting it. With ReturnValue::UpdatedNew, DynamoDB hands us back the new counter value, which is exactly what we need.
Phew, that was a lot! We now have a complete middleware in our hands: the Layer factory, the Service impl with all its branches, the response helpers, and the storage trait with its DynamoDB-backed implementation. The only question left is the obvious one: how do we know any of it actually works? Time to write some tests.
Testing the middleware
Remember why we bothered to put RateLimitStore behind a trait back in the layer section? This is the payoff. Because RateLimitService is generic over the trait, the tests can plug in a plain in-memory mock and exercise the entire middleware (IP extraction, bucket math, over-limit short-circuit, fail-closed path) without ever touching DynamoDB. The middleware logic and the storage adapter end up living in different test budgets: one runs in milliseconds against an in-memory HashMap, the other only when you genuinely want an end-to-end deploy. This is a pattern worth stealing for any middleware that touches external state: keep the I/O behind a small trait, accept it as a generic, and you get fast deterministic unit tests almost for free.
Here is the mock and two representative tests (the full suite is in the repo):
#[cfg(test)]mod tests {11 collapsed lines
use super::*; use http::{Request, StatusCode}; use lambda_http::aws_lambda_events::apigw::{ ApiGatewayV2httpRequestContext, ApiGatewayV2httpRequestContextHttpDescription, }; use lambda_http::request::RequestContext; use lambda_http::tower::ServiceExt; use lambda_http::RequestExt; use std::convert::Infallible; use std::sync::Mutex; use std::time::Duration;
struct MockRateLimitStore { counters: Mutex<std::collections::HashMap<String, u32>>, }
#[async_trait::async_trait] impl RateLimitStore for MockRateLimitStore { async fn increment_and_get( &self, _table_name: &str, pk: &str, _ttl: u64, ) -> Result<u32, RateLimitStoreError> { let mut counters = self.counters.lock().unwrap(); let count = counters.entry(pk.to_string()).or_insert(0); *count += 1; Ok(*count) } }
19 collapsed lines
async fn ok_handler(_req: Request<Body>) -> Result<Response<Body>, Infallible> { Ok(Response::builder().status(200).body(Body::Empty).unwrap()) }
// `extract_ip` reads the source IP from the API Gateway request // context, so the test request needs a populated `ApiGatewayV2` // context. fn request_with_ip(ip: &str) -> Request<Body> { let mut http = ApiGatewayV2httpRequestContextHttpDescription::default(); http.source_ip = Some(ip.to_string()); let mut ctx = ApiGatewayV2httpRequestContext::default(); ctx.http = http;
let request = Request::builder() .uri("http://example.com/") .body(Body::Empty) .unwrap(); request.with_request_context(RequestContext::ApiGatewayV2(ctx)) }
#[tokio::test] async fn under_limit_calls_inner_service() { let config = Arc::new(RateLimitConfig { table_name: "t".into(), max_requests: 10, window_duration: Duration::from_secs(60), }); let store: Arc<dyn RateLimitStore> = Arc::new(MockRateLimitStore { counters: Mutex::new(Default::default()), }); let service = RateLimitService::with_store(lambda_http::tower::service_fn(ok_handler), store, config);
let response = service.oneshot(request_with_ip("203.0.113.1")).await.unwrap();
assert_eq!(response.status(), StatusCode::OK); assert_eq!(response.headers().get("X-RateLimit-Remaining").unwrap(), "9"); }
#[tokio::test] async fn over_limit_returns_429() { let config = Arc::new(RateLimitConfig { table_name: "t".into(), max_requests: 1, window_duration: Duration::from_secs(60), }); let store: Arc<dyn RateLimitStore> = Arc::new(MockRateLimitStore { counters: Mutex::new(Default::default()), });
let service = RateLimitService::with_store( lambda_http::tower::service_fn(ok_handler), Arc::clone(&store), Arc::clone(&config), ); let first = service.oneshot(request_with_ip("203.0.113.2")).await.unwrap(); assert_eq!(first.status(), StatusCode::OK);
let service = RateLimitService::with_store(lambda_http::tower::service_fn(ok_handler), store, config); let second = service.oneshot(request_with_ip("203.0.113.2")).await.unwrap(); assert_eq!(second.status(), StatusCode::TOO_MANY_REQUESTS); }}The with_store constructor is a #[cfg(test)] helper that lets tests inject the mock:
#[cfg(test)]impl<S> RateLimitService<S> { fn with_store( inner: S, store: Arc<dyn RateLimitStore>, config: Arc<RateLimitConfig>, ) -> Self { Self { inner, store, config } }}No local DynamoDB, no network, no flaky tests. Every edge case (under limit, over limit, different IPs, store errors, missing IP) can be covered in milliseconds. This is the main reason I always reach for the store-trait pattern in Lambda middleware that touches external state.
Adding customisable error responses
The basic version above ships fixed 429 and 503 bodies. That is fine for “drop in and forget”, but the moment a caller wants to add a CORS header to the 429, or attach a request id, or swap the body for an RFC 7807 problem document, they either have to fork the crate or stack another middleware on top whose only job is to intercept and rewrite the limiter’s responses. Awkward either way.
The fix is a small extension hook for each of the two bail-out branches. We give RateLimitLayer two optional callbacks, on_over_limit and on_unavailable. Each one receives the incoming request and the pre-built default response, and returns a response. Callers who want the default get it for free (the default callback just hands the pre-built response back). Callers who want a tweak only mutate the bits they care about. Callers who want to replace the response entirely can ignore the input and build their own.
The shape, in types:
/// Information passed to a custom over-limit response builder.pub struct OverLimitCtx { pub ip: IpAddr, pub limit: u32, pub reset_at: u64, pub retry_after: u64,}
pub type OverLimitFn = Arc<dyn Fn(&Request<Body>, Response<Body>, &OverLimitCtx) -> Response<Body> + Send + Sync>;
pub type UnavailableFn = Arc<dyn Fn(&Request<Body>, Response<Body>) -> Response<Body> + Send + Sync>;RateLimitLayer and RateLimitService both grow two new fields (over_limit: OverLimitFn, unavailable: UnavailableFn), the defaults pass the response through unchanged, and RateLimitLayer gains two builder methods for swapping them out:
impl RateLimitLayer { pub fn on_over_limit<F>(mut self, f: F) -> Self where F: Fn(&Request<Body>, Response<Body>, &OverLimitCtx) -> Response<Body> + Send + Sync + 'static, { self.over_limit = Arc::new(f); self }
pub fn on_unavailable<F>(mut self, f: F) -> Self where F: Fn(&Request<Body>, Response<Body>) -> Response<Body> + Send + Sync + 'static, { self.unavailable = Arc::new(f); self }}The bail-out branches in call change from returning the pre-built response directly to passing it through the callback. To keep the request available to the callback (which now needs to look at it), call clones the request before handing it off to the inner service:
let request_for_bailout = request.clone();let inner_future = self.inner.call(request);// ...inside the async block...return Ok(unavailable(&request_for_bailout, build_unavailable_response()));// ...and on the over-limit path...let ctx = OverLimitCtx { ip, limit, reset_at, retry_after: seconds_until_reset };let pre_built = build_over_limit_response(&ctx);return Ok(over_limit(&request_for_bailout, pre_built, &ctx));The clone is the price we pay for the ergonomics. In practice it is cheap: lambda_http::Body is Arc-backed, so cloning the request duplicates the headers, URI, and method but only bumps a refcount on the body. It only matters in degenerate cases (huge header maps, or swapping Request<Body> out for a custom payload that does not share its inner buffers); if you hit one, replace the clone with a small “request metadata” struct holding only the bits the callbacks need.
The full version of all this lives in the companion repo’s src/rate_limit.rs, including a couple of extra unit tests that prove the override path works (e.g. an on_over_limit that adds a custom header, an on_unavailable that replaces the 503 with a 502).
This is a pattern worth stealing for any reusable middleware: ship sensible defaults, expose tasteful override hooks, and pre-populate as much of the result as you can so the hooks have something to tweak.
Wiring it all up in lambdas/hello
Everything we have written so far is essentially a small library. Now we want an actual Lambda app that uses it, so we can deploy it on AWS and watch it rate-limit real traffic. The handler itself is split across two files: one for the request/response logic and one for the runtime wiring.
use lambda_http::{Body, Error, Request, Response};use serde_json::json;
pub async fn function_handler(_request: Request) -> Result<Response<Body>, Error> { let body = json!({ "message": "hello from your friendly Rust Lambda function" }).to_string(); Ok(Response::builder() .status(200) .header("content-type", "application/json") .body(body.into())?)}This is exactly why we worked so hard to build the middleware in the first place. The handler does not import RateLimitLayer, does not see DynamoDB, does not know the concept of a quota; it is a trivial hello-world that just returns a JSON body. We want our handlers to stay as pure as possible, focused entirely on business logic (in this case the world’s most boring “hello”), while every cross-cutting concern (rate limiting today, auth, logging, CORS, request validation tomorrow) lives in dedicated middleware code that we can layer on top without ever touching the handler again. All that interesting wiring lives in main.rs:
8 collapsed lines
use std::time::Duration;
use lambda_http::tower::ServiceBuilder;use lambda_http::{run, service_fn, tracing, Error};use rust_lambda_middleware_example::{RateLimitConfig, RateLimitLayer};
mod http_handler;use http_handler::function_handler;
#[tokio::main]async fn main() -> Result<(), Error> { tracing::init_default_subscriber();
let aws_config = aws_config::load_from_env().await; let dynamodb_client = aws_sdk_dynamodb::Client::new(&aws_config);
let table_name = std::env::var("RATE_LIMIT_TABLE_NAME").expect("RATE_LIMIT_TABLE_NAME must be set"); let max_requests: u32 = std::env::var("RATE_LIMIT_MAX_REQUESTS") .ok() .and_then(|v| v.parse().ok()) .unwrap_or(10); let window_secs: u64 = std::env::var("RATE_LIMIT_WINDOW_SECS") .ok() .and_then(|v| v.parse().ok()) .unwrap_or(900); let window_duration = Duration::from_secs(window_secs);
let rate_limit = RateLimitLayer::new( RateLimitConfig { table_name, max_requests, window_duration }, dynamodb_client, );
let service = ServiceBuilder::new() .layer(rate_limit) .service(service_fn(function_handler));
run(service).await}The shape that matters is the last three statements: ServiceBuilder stacks layers, service_fn wraps our async fn function_handler as a Service, and lambda_http::run drives the whole thing from the Lambda runtime.
Add more layers (logging, auth, CORS) by chaining more .layer(...) calls. That is the whole middleware story.
Tower layers from the wider ecosystem compose just as cleanly. For example, to put CORS in front of the rate limiter you would add tower_http::cors::CorsLayer to your dependencies and write:
use lambda_http::tower::ServiceBuilder;use tower_http::cors::CorsLayer;
let service = ServiceBuilder::new() .layer(CorsLayer::permissive()) // outer: runs first on the way in .layer(rate_limit) // inner: our middleware .service(service_fn(handler));The same Layer and Service traits we used to write the rate limiter let it slot in next to anything else in the Tower ecosystem (provided, of course, that the request and response types of the surrounding services line up with what each layer expects).
How can a generic tower layer like CorsLayer work out of the box on a Lambda?
It feels almost too convenient: tower-http’s CorsLayer was written for general HTTP services (axum, hyper, anything), and yet we drop it straight into a Lambda stack and it just works. There is no Lambda adapter in tower-http, no shim, no glue layer. Why does it compose?
The answer is that everyone in this picture agrees on the same request and response types. Tower-http defines CorsLayer against the http crate’s generic Request<ReqBody> and Response<ResBody> types:
impl<S, ReqBody, ResBody> Service<Request<ReqBody>> for Cors<S>where S: Service<Request<ReqBody>, Response = Response<ResBody>>, ResBody: Default,{ /* ... */ }And lambda_http does not invent its own request/response types; it just specialises the same http types with its own Body:
pub type Request = http::Request<Body>;So a lambda_http::Request is an http::Request, with the body parameter pinned to lambda_http::Body. Tower-http’s CorsLayer sees an http::Request<lambda_http::Body> go past, the trait bounds match, and the layer composes with no fuss.
This is one of the quietly large benefits of having a high-level abstraction like lambda_http in front of the runtime. We are not just buying an ergonomic API for parsing requests and producing HTTP-compatible responses; we are buying into the entire framework- agnostic ecosystem that already exists around the http crate and tower. CORS, compression, request IDs, structured logging, retries, timeouts, auth: most of what tower-http and the wider tower ecosystem ships will compose with our Lambda the same way CorsLayer just did, with no Lambda-specific adapter in sight.
Deploying with SAM
Let us ship this. Here is a template.yaml that provisions the DynamoDB table, builds the Rust Lambda with cargo-lambda, and wires up an HTTP API endpoint:
AWSTemplateFormatVersion: '2010-09-09'Transform: AWS::Serverless-2016-10-31Description: Hello-world Rust Lambda with a tower-based DynamoDB rate limit middleware.
Parameters: MaxRequests: Type: Number Default: 10 WindowSecs: Type: Number Default: 900
Globals: Function: Timeout: 5 MemorySize: 128
Resources: RateLimitTable: Type: AWS::DynamoDB::Table Properties: BillingMode: PAY_PER_REQUEST AttributeDefinitions: - AttributeName: pk AttributeType: S KeySchema: - AttributeName: pk KeyType: HASH TimeToLiveSpecification: # 1 AttributeName: ttl Enabled: true
HelloFunction: Type: AWS::Serverless::Function Metadata: BuildMethod: rust-cargolambda # 2 Properties: FunctionName: !Sub ${AWS::StackName}-hello CodeUri: lambdas/hello Handler: bootstrap Runtime: provided.al2023 Architectures: # 3 - arm64 Environment: Variables: RATE_LIMIT_TABLE_NAME: !Ref RateLimitTable RATE_LIMIT_MAX_REQUESTS: !Ref MaxRequests RATE_LIMIT_WINDOW_SECS: !Ref WindowSecs Policies: - DynamoDBCrudPolicy: # 4 TableName: !Ref RateLimitTable Events: Hello: Type: HttpApi Properties: Path: / Method: get
Outputs: HelloApi: Value: !Sub https://${ServerlessHttpApi}.execute-api.${AWS::Region}.amazonaws.com/ RateLimitTableName: Value: !Ref RateLimitTableFour pieces worth calling out:
- The DynamoDB table has
TimeToLiveSpecificationon attlattribute, so DynamoDB will eventually delete expired counter rows for us. AWS documents TTL deletion as automatic but eventual (typically within a few days), which is fine here because we never reuse old buckets, but do not lean on TTL for precise expiry. Metadata: BuildMethod: rust-cargolambdatellssam buildto delegate the build to cargo-lambda, which produces a correctly-namedbootstrapbinary for theprovided.al2023runtime.CodeUri: lambdas/hellopoints SAM at our Lambda crate’s directory.Architectures: arm64does double duty: AWS deploys the function on Graviton, and cargo-lambda’s SAM hook reads it to cross-compile the binary foraarch64. Important: this property must live on the function itself (not inGlobals); cargo-lambda’s hook does not seeGlobals-level overrides, and the resulting arch mismatch shows up at runtime as the lovelyRuntime.InvalidEntrypointerror.DynamoDBCrudPolicyis convenient for the tutorial but broader than the function actually needs; for production, scope the policy down todynamodb:UpdateItemon this one table.
To deploy, install cargo-lambda and the AWS SAM CLI, then:
sam validate && sam build && sam deploy --guidedsam validate catches template syntax errors before you spend time on the build, sam build invokes cargo-lambda to cross-compile the binary, and sam deploy --guided walks you through stack-name and region selection on the first run, remembering your choices in a local samconfig.toml so subsequent deploys can drop the --guided flag. When the deploy finishes, grab the HelloApi URL from the stack outputs.
Now let us poke it. On the first call:
curl -i https://<your-api-id>.execute-api.<region>.amazonaws.com/This should output something like:
HTTP/2 200content-type: application/jsonx-ratelimit-limit: 10x-ratelimit-remaining: 9x-ratelimit-reset: 1745081400
{"message":"hello from your friendly Rust Lambda function"}Keep calling:
for i in $(seq 1 12); do curl -i https://<your-api-id>.execute-api.<region>.amazonaws.com/doneRequests 1 through 10 come back 200 with X-RateLimit-Remaining counting down. Request 11 trips the limiter:
HTTP/2 429content-type: application/jsonretry-after: 732x-ratelimit-limit: 10x-ratelimit-remaining: 0x-ratelimit-reset: 1745081400
{"error":"rate limit exceeded","retry_after":732}Wait out the window (or redeploy with a smaller WindowSecs parameter), and you are back at 10 remaining. You can peek at the raw counters if you are curious:
aws dynamodb scan --table-name <stack-name>-RateLimitTable-<suffix>Hooray! Our rate limiter works as expected! 🎉
Wrapping up
If this post has done its job, two ideas should now be sitting next to each other in your head:
- The middleware pattern is worth every bit of hype it has accumulated in the Node.js / Python / Go web worlds, and it fits Lambda perfectly. It keeps handlers small, composable, and easy to test. That was a huge part of the appeal of middy back in 2017, and the same property is just as valuable today.
- Rust Lambda has it too, sitting right there in the runtime. Because the
aws-lambda-rust-runtimeis built on tokio, every handler is already a towerService; writing a middleware is a matter of implementing two traits and chaining aServiceBuilder.
Once you start thinking in layers, it gets addictive. A real Rust Lambda typically stacks auth, logging, request validation, response signing, CORS, rate limiting, and more, leaving the handler to do the one thing it actually cares about. That is the same shape middy gives Node.js, and it is well within reach in Rust too.
Some next steps you might enjoy:
- Add an authentication verification layer.
- Then you can move the limiter key to something that survives IP changes for authenticated users (e.g. swap the IP-based key for a user claim).
- Trade the fixed window for a token-bucket implementation; the middleware skeleton stays identical.
- Try the same pattern on a non-HTTP Lambda (SQS, EventBridge); the
lambda_runtimecrate exposes the sameService-based API.
As a reminder, all the code in this post is collected in a working sample at github.com/lmammino/rust-lambda-middleware-example. Clone it, sam deploy, and you are five minutes away from a working example in your own AWS account.
Further reading
- middy.js.org: the Node.js middleware engine that started this whole rabbit hole for me.
- tower on crates.io and the tower docs.
lambda_httpon docs.rs: the HTTP abstraction on top of the Rust Lambda runtime.aws-lambda-rust-runtime: where the whole story starts.- cargo-lambda: the build tool that makes Rust Lambda practical.
- Warren Parad’s Exceeding AWS rate-limiting, CloudFront, usage plans for a broader tour of rate-limit tradeoffs on AWS.
- GitHub’s REST rate limit docs: a practical example of how to expose rate limit state to clients.
- My older Rust Lambda pieces: why Rust for Lambda and coauthoring a book about Rust and Lambda.
Happy layering, and if you end up writing your own Lambda middleware, I would love to hear about them on Bluesky. 🦋